Free OCR Screenshot
Recognize text from images and pdf files using the Tesseract OCR Engine based on the cloud technology.
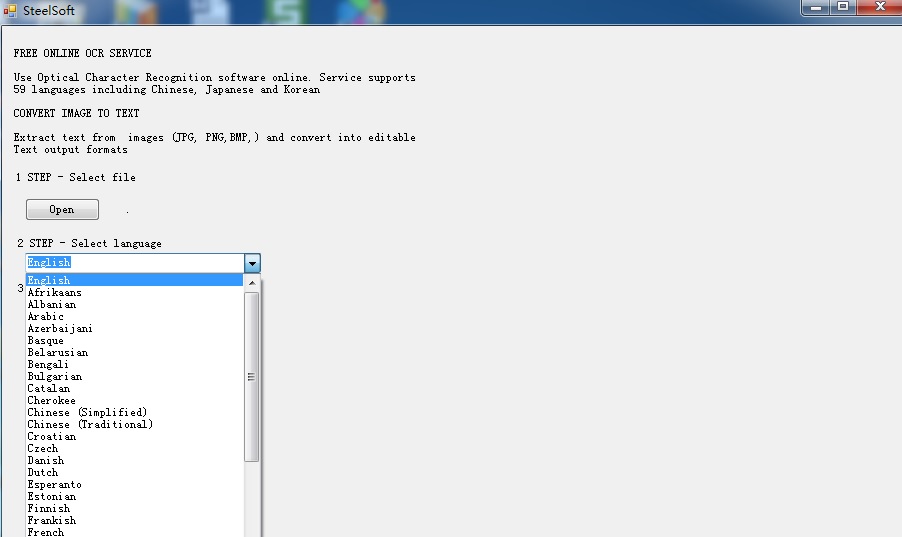
Use Optical Character Recognition software online. Service supports 59 languages including Chinese, Japanese and Korean. Extract text from images (JPG, PNG,BMP,TIF) and pdf files, convert into editable Text output formats.
It is based on cloud technology, and very famous OCR engine( Tesseract OCR Engine), so there is only hundreds of KB in size, but it can extract text in 59 languages, from the images and pdf files.
It supports more languages: Bulgarian, Catalan, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovene, Spanish, Swedish, Tagalog, Turkish, Ukrainian, Vietnamese etc .
Back to Free OCR Details page
- Ocr Free To Use
- Free Ocr B
- Dl Free Ocr
- Free Ocr For Pc
- Free Ocr Best
- Free Ocr Os X
- Free Ocr Pro
- Ocr Free Tables
- Hebrew Ocr Free
- Mac Free Ocr For Hp